Het bouwen van een Nederlandse QA-bot op consumentenhardware
Sinds de introductie van ChatGPT hebben grote taalmodellen (LLM's) aanzienlijk aan populariteit gewonnen. Bijvoorbeeld, tools zoals Copilot die helpen bij het uitvoeren van taken, worden steeds gebruikelijker. Ook bedrijven maken gebruik van LLM's in hun processen om kosten te besparen en manuren te verminderen.
2 sep 2024
De overheid is geïnteresseerd in het benutten van deze opkomende technologie vanwege haar potentieel, maar ze staat voor enkele uitdagingen. Een belangrijk probleem is databeveiliging en privacy, vooral bij het gebruik van gesloten bronmodellen op externe servers. Een andere uitdaging is dat de meeste LLM's goed presteren in het Engels, maar beperkt zijn in hun vaardigheid in het Nederlands, waardoor het voor de Nederlandse overheid moeilijk is om deze technologie over te nemen.
Om deze problemen aan te pakken, hebben we een open-source LLM op onze eigen hardware ingezet als basis voor een Nederlandse QA-bot. Dit dient als eerste stap om aan te tonen dat we zo'n systeem lokaal kunnen draaien, waarmee we de zorgen over databeveiliging overwinnen, en dat onze bot veelbelovende vloeiendheid in het Nederlands toont.
Uitdagingen
Het ontwikkelen van een Nederlandse Vraag-Antwoord (QA) bot die efficiënt opereert op eigen consumentenniveau hardware bracht verschillende uitdagingen met zich mee, met name in het omgaan met de finesses van de Nederlandse taal en het garanderen van optimale prestaties.
De Oplossing
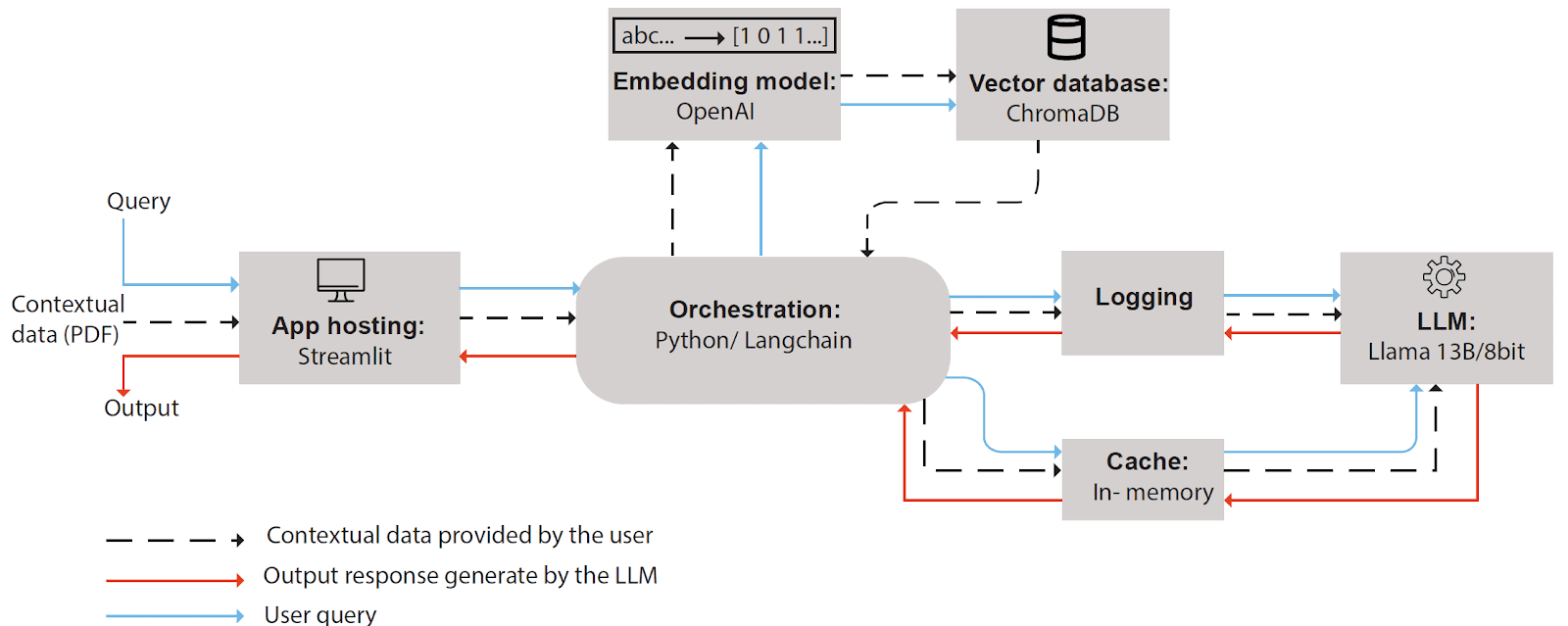
Door gebruik te maken van geavanceerde technieken, hebben we een schaalbare QA-bot gecreëerd met behulp van een 8-bits gekwantiseerd 13 miljard-parameter Llama groot taalmodel (LLM) en een Retrieval-Augmented Generation (RAG) architectuur. Deze architectuur bestond uit verschillende belangrijke componenten, zoals weergegeven in Figuur 1 hieronder:
Figuur 1: Indeling van de RAG Architectuur

De RAG architectuur omvatte:
Een ChromaDB vector database verbonden met een OpenAI tekst embedding model (text-embedding-3-large) voor het vectoriseren van contextuele data geleverd via een Streamlit UI.
In-memory caching voor het opslaan en ophalen van historische prompts.
Een loggingmodule voor het bewaken van de applicatieprestaties en foutopsporing.
De Llama 13B LLM, die reacties genereerde op basis van de contextuele data.
De gehele pijpleiding gecoördineerd met Langchain in Python, geactiveerd door gebruikersvragen via de UI.
De bot werd gebouwd en ingezet op een consumentenniveau desktop uitgerust met een Intel i9 9900K processor, een NVIDIA RTX2070 GPU en 16 GB RAM. Het 13B Llama model, getraind op een beperkte corpus van Nederlands, werd fijn afgestemd met Nederlandse instructies. Door gebruik te maken van een 8-bits gekwantiseerde versie van het model werd de geheugeneis gereduceerd tot 9 GB (52GB), waardoor het efficiënt kon draaien op de beschikbare hardware.
Het Resultaat
De Nederlandse QA-bot demonstreerde hoge precisie met een cosinus overeenkomst van meer dan 0,8 in vergelijking met ChatGPT-3.5-responsen. Ondanks de beperkingen van consumenten hardware was de prestatie van de bot robuust en betrouwbaar, wat een significante stap voorwaarts markeerde naar meer toegankelijke en efficiënte natuurlijke taalverwerking (NLP) oplossingen.
Wat We Hebben Geleerd
Balanceren van rekenefficiëntie met taalvaardigheid was essentieel. Het gebruik van een gekwantiseerd model bleek kosteneffectief zonder aan prestatie in te boeten. De RAG-architectuur integreerde contextuele informatie effectief, waardoor de nauwkeurigheid van de bot's reacties verbeterde.
Wat We Het Beste Vonden
De inzet van de bot op lokale hardware, waardoor dure serverparken vermeden werden. Betrouwbare prestaties leveren op breed toegankelijke hardware benadrukt het potentieel van deze relatief nieuwe technologie voor overheidsgebruik, met oog op databeveiliging en privacy.
Voor meer gedetailleerde inzichten in het project, bezoek de originele LinkedIn-post.

